![]()
The DP-500 PDF Dumps Greatest for the Microsoft Exam Study Guide!
Read Online DP-500 Test Practice Test Questions Exam Dumps
The DP-500 exam covers a wide range of topics such as designing and implementing big data solutions, implementing Azure data storage solutions, designing and implementing data processing solutions, and designing and implementing Power BI solutions. DP-500 exam also evaluates the candidate's ability to implement security and compliance solutions, manage and monitor the solutions, and troubleshoot issues that arise during implementation. Passing DP-500 exam requires a deep understanding of the Azure ecosystem and the ability to utilize its services and tools to deliver enterprise-scale analytics solutions to clients.
Microsoft DP-500 Certification Exam is a great way for data professionals to demonstrate their expertise in designing and implementing enterprise-scale analytics solutions using Microsoft Azure and Microsoft Power BI. It is also an excellent way to enhance their career prospects and increase their earning potential. With the increasing demand for data professionals who can design and implement analytics solutions using Microsoft technologies, the Microsoft DP-500 Certification Exam is a valuable asset for anyone looking to advance their career in this field.
Microsoft DP-500 exam is a valuable certification for professionals who are looking to advance their careers in the field of enterprise-scale analytics solutions. With the right preparation and experience, candidates can successfully pass the exam and demonstrate their expertise to potential employers.
NEW QUESTION # 16
You need to ensure that the new process for deploying reports and datasets to the User Experience workspace meets the technical requirements.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.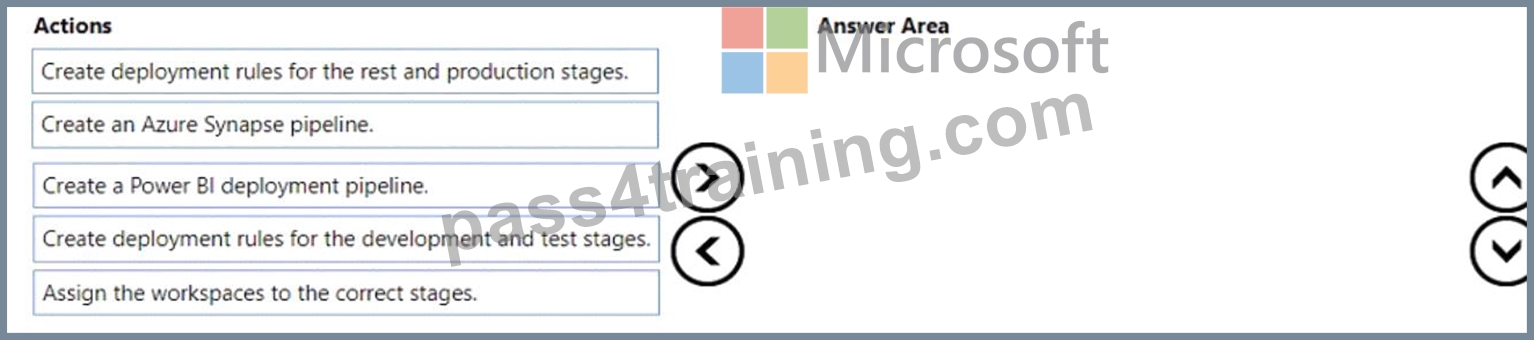
Answer:
Explanation:
Explanation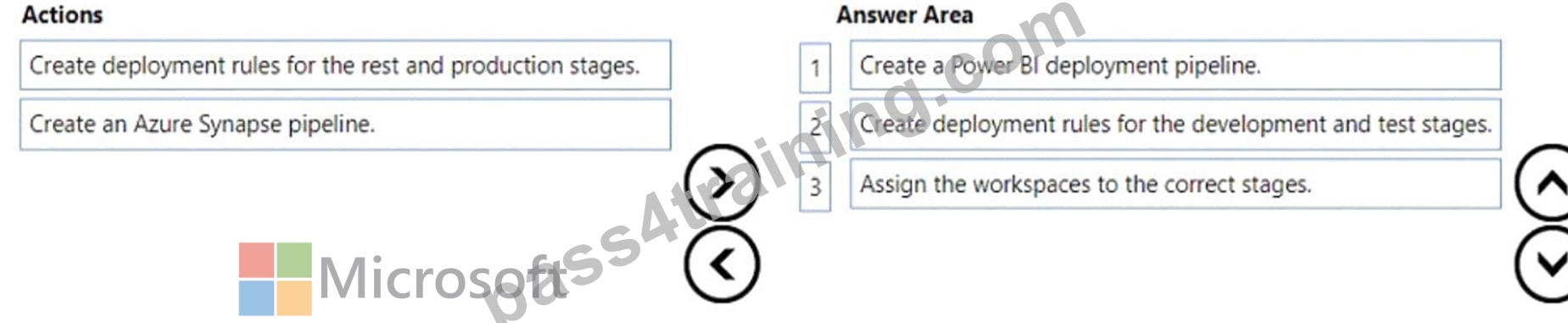
NEW QUESTION # 17
You need to configure a source control solution for Azure Synapse Analytics. The solution must meet the
following requirements:
* Code must always be merged to the main branch before being published, and the main branch must be used
for publishing resource
* The workspace templates must be stored in the publish branch.
* A branch named dev123 will be created to support the development of a new feature.
What should you do? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Answer:
Explanation:
NEW QUESTION # 18
You have the following Python code in an Apache Spark notebook.
Which type of chart will the code produce?
- A. a stacked bar chart
- B. a pie chart
- C. an area chart
- D. a bar chart
Answer: C
Explanation:
Explanation
The matplotlib.pyplot.fill_between function fills the area between two horizontal curves.
The curves are defined by the points (x, y1) and (x, y2). This creates one or multiple polygons describing the filled area.
Reference: https://matplotlib.org/3.5.0/api/_as_gen/matplotlib.pyplot.fill_between.html
NEW QUESTION # 19
What should you configure in the deployment pipeline?
- A. a selective deployment
- B. auto-binding
- C. a data source rule
- D. a backward deployment
Answer: B
NEW QUESTION # 20
You have a Power Bl dataset named Dataset1 that uses DirectQuery against an Azure SQL database named DB1. DB1 is a transactional database in the third normal form.
You need to recommend a solution to minimize how long it takes to execute the query. The solution must maintain the current functionality. What should you include in the recommendation?
- A. Remove the relationships from Dataset1.
- B. Normalize the tables in DB1.
- C. Create calculated columns in Dataset1.
- D. Denormalize the tables in DB1.
Answer: D
Explanation:
Explanation
Denormalize to improve query performance.
Note: Normalization prevents data duplications, preserves disk space, and improves the performance of the disk I/O operations. The downside of the normalization is that the queries based on these normalized tables require more table joins.
Schema denormalization (i.e. consolidation of some dimension tables) for such databases can significantly reduce costs of the analytical queries and improve the performance.
Reference:
https://www.mssqltips.com/sqlservertip/7114/denormalization-dimensions-synapse-mapping-data-flow/
NEW QUESTION # 21
Note: This question is part of a series of questions that present the same scenario. Each question in the series
contains a unique solution that might meet the stated goals. Some question sets might have more than one
correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions
will not appear in the review screen.
You have the Power BI data model shown in the exhibit (Click the Exhibit tab.)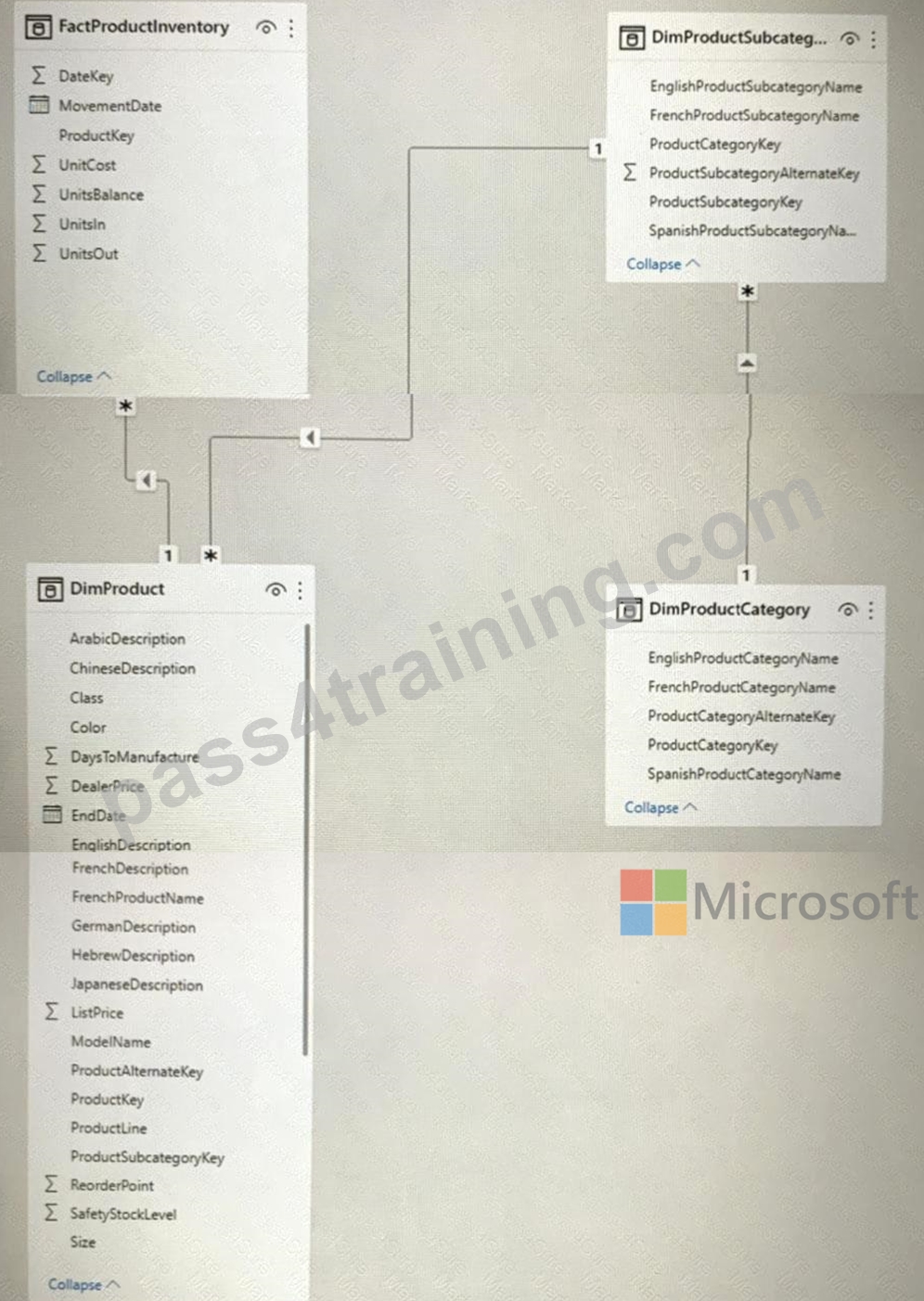
Users indicate that when they build reports from the data model, the reports take a long time to load.
You need to recommend a solution to reduce the load times of the reports.
Solution: You recommend denormalizing the data model.
Does this meet the goal?
- A. No
- B. Yes
Answer: A
NEW QUESTION # 22
You are creating a Python visual in Power Bl Desktop.
You need to retrieve the value of a column named Unit Price from a DataFrame.
How should you reference the Unit Price column in the Python code?
- A. dataset['Unit Price']
- B. ('Unit Price')
- C. data = [Unit Price]
- D. pandas.DataFrame('Unit Price')
Answer: D
Explanation:
You can retrieve a column in a pandas DataFrame object by using the DataFrame object name, followed by the label of the column name in brackets.
So if the DataFrame object name is dataframe1 and the column we are trying to retrieve the 'X' column, then we retrieve the column using the statement, dataframe1['X'].
Here's a simple Python script that imports pandas and uses a data frame:
import pandas as pd
data = [['Alex',10],['Bob',12],['Clarke',13]]
df = pd.DataFrame(data,columns=['Name','Age'],dtype=float)
print (df)
When run, this script returns:
Name Age
0 Alex 10.0
1 Bob 12.0
2 Clarke 13.0
NEW QUESTION # 23
Your company is migrating its current, custom-built reporting solution to Power BI.
The Power BI tenant must support the following scenarios:
40 reports that will be embedded in external websites. The websites control their own security. The reports will be consumed by 50 users monthly.
Forty-five users that require access to the workspaces and apps in the Power BI Admin portal. Ten of the users must publish and consume datasets that are larger than 1 GB.
Ten developers that require Text Analytics transformations and paginated reports for datasets. An additional 15 users will consume the reports.
You need to recommend a licensing solution for the company. The solution must minimize costs.
Which two Power BI license options should you include in the recommendation? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
- A. 35 Premium per user
- B. 35 Pro
- C. 70 Premium per user
- D. 70 Pro
- E. one Premium
- F. one Embedded
Answer: A,B,E
Explanation:
Explanation
B:
Free - 40 reports that will be embedded in external websites. The websites control their own security.
Free - The reports will be consumed by 50 users monthly.
Free + 1 Premium for the Worspace -Forty-five users that require access to the workspaces and apps in the Power BI Admin portal.
F: Ten of the users must publish and consume datasets that are larger than 1 GB.
Ten developers that require Text Analytics transformations and paginated reports for datasets. An additional
15 users will consume the reports.
Power BI Premium per user features and capabilities
* Pixel perfect paginated reports are available for operational reporting capabilities based on SSRS technology. Users can create highly formatted reports in various formats such as PDF and PPT, which are embeddable in applications and are designed to be printed or shared.
Note: There are three kinds of Power BI per-user licenses: Free, Pro, and Premium Per User.
Power BI (free): Access to content in My Workspace
Power BI (free) + Workspace is Premium: Consume content shared with them Power BI Pro: Publish content to other workspaces, share dashboards, subscribe to dashboards and reports, share with users who have a Pro license Power BI Pro + Workspace is Premium: Distribute content to users who have free licenses Power BI Premium Per User: Publish content to other workspaces, share dashboards, subscribe to dashboards and reports, share with users who have a Premium Per User license Power BI Premium Per User + Workspace is Premium: Distribute content to users who have free and Pro licenses Reference: https://docs.microsoft.com/en-us/power-bi/fundamentals/service-features-license-type
NEW QUESTION # 24
You have five Power Bl reports that contain R script data sources and R visuals.
You need to publish the reports to the Power Bl service and configure a daily refresh of datasets.
What should you include in the solution?
- A. an on-premises data gateway (personal mode)
- B. an on-premises data gateway (standard mode)
- C. a Power Bl Embedded capacity
- D. a workspace that connects to an Azure Data Lake Storage Gen2 account
Answer: A
Explanation:
Explanation
To schedule refresh of your R visuals or dataset, enable scheduled refresh and install an on-premises data gateway (personal mode) on the computer containing the workbook and R.
Reference: https://docs.microsoft.com/en-us/power-bi/connect-data/desktop-r-in-query-editor
NEW QUESTION # 25
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are using an Azure Synapse Analytics serverless SQL pool to query a collection of Apache Parquet files by using automatic schema inference. The files contain more than 40 million rows of UTF-8-encoded business names, survey names, and participant counts. The database is configured to use the default collation.
The queries use open row set and infer the schema shown in the following table.
You need to recommend changes to the queries to reduce I/O reads and tempdb usage.
Solution: You recommend using openrowset with to explicitly define the collation for businessName and surveyName as Latim_Generai_100_BiN2_UTF8.
Does this meet the goal?
- A. Yes
- B. No
Answer: A
Explanation:
Explanation
Query Parquet files using serverless SQL pool in Azure Synapse Analytics.
Important
Ensure you are using a UTF-8 database collation (for example Latin1_General_100_BIN2_UTF8) because string values in PARQUET files are encoded using UTF-8 encoding. A mismatch between the text encoding in the PARQUET file and the collation may cause unexpected conversion errors. You can easily change the default collation of the current database using the following T-SQL statement: alter database current collate Latin1_General_100_BIN2_UTF8'.
Note: If you use the Latin1_General_100_BIN2_UTF8 collation you will get an additional performance boost compared to the other collations. The Latin1_General_100_BIN2_UTF8 collation is compatible with parquet string sorting rules. The SQL pool is able to eliminate some parts of the parquet files that will not contain data needed in the queries (file/column-segment pruning). If you use other collations, all data from the parquet files will be loaded into Synapse SQL and the filtering is happening within the SQL process. The Latin1_General_100_BIN2_UTF8 collation has additional performance optimization that works only for parquet and CosmosDB. The downside is that you lose fine-grained comparison rules like case insensitivity.
Reference: https://docs.microsoft.com/en-us/azure/synapse-analytics/sql/query-parquet-files
NEW QUESTION # 26
You plan to create a Power Bl report that will use an OData feed as the data source. You will retrieve all the entities from two different collections by using the same service root The OData feed is still in development. The location of the feed will change once development is complete.
The report will be published before the OData feed development is complete.
You need to minimize development effort to change the data source once the location changes.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.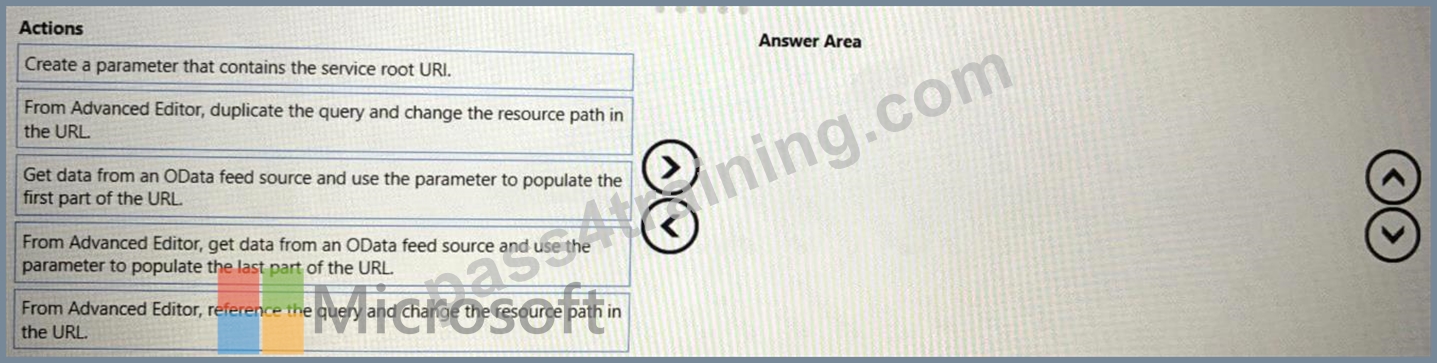
Answer:
Explanation:
Explanation
Graphical user interface, text, application Description automatically generated
Step 1: Create a parameter that contains the service root URI
Step 2: Get data from OData feed source and use the parameter to populate the first part of the URL.
The URI is in the first part of the query.
Example: let
Source = OData.Feed
("https://analytics.dev.azure.com/{organization}/{project}/_odata/v3.0-preview/WorkItemSnapshot? "
&"$apply=filter( "
&"WorkItemType eq 'Bug' "
&"and StateCategory ne 'Completed' "
&"and startswith(Area/AreaPath,'{areapath}') "
&"and DateValue ge {startdate} "
&") "
&"/groupby( "
&"(DateValue,State,WorkItemType,Priority,Severity,Area/AreaPath,Iteration/IterationPath,AreaSK), "
&"aggregate($count as Count) "
&") "
,null, [Implementation="2.0",OmitValues = ODataOmitValues.Nulls,ODataVersion = 4]) in Source Box 3: From Advanced Editor, duplicate the query and change the resource path in the URL.
Choose Get Data, and then Blank Query.
From the Power BI Query editor, choose Advanced Editor.
The Advanced Editor window opens.
Edit the query.
Etc.
Reference: https://docs.microsoft.com/en-us/azure/devops/report/powerbi/odataquery-connect
NEW QUESTION # 27
You have the following code in an Azure Synapse notebook.
Use the drop-down menus to select the answer choice that completes each statement based on the information presented in the code.
NOTE: Each correct selection is worth one point.
Answer:
Explanation: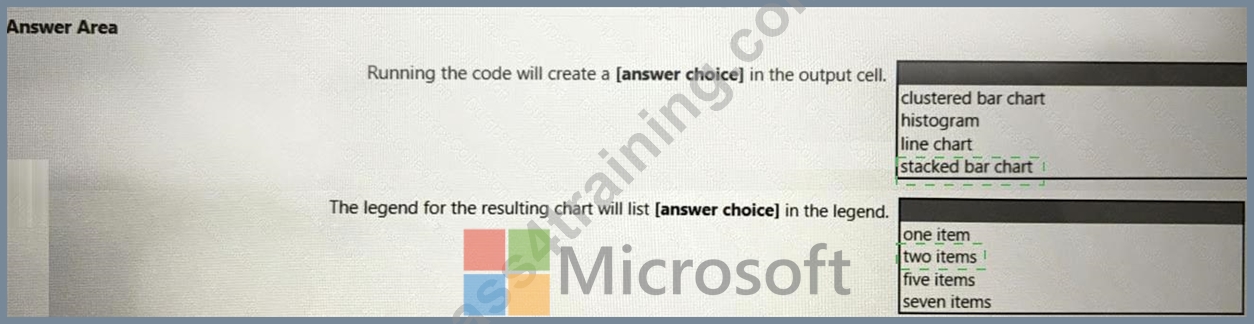
Explanation
Box 1: stacked bar chart
matplotlib.pyplot.bar makes a bar plot.
The bars are positioned at x with the given alignment. Their dimensions are given by height and width. The vertical baseline is bottom (default 0).
Many parameters can take either a single value applying to all bars or a sequence of values, one for each bar.
Stacked bars can be achieved by passing individual bottom values per bar.
Stacked bar chart
This is an example of creating a stacked bar plot with error bars using bar. Note the parameters yeer used for error bars, and bottom to stack the women's bars on top of the men's bars.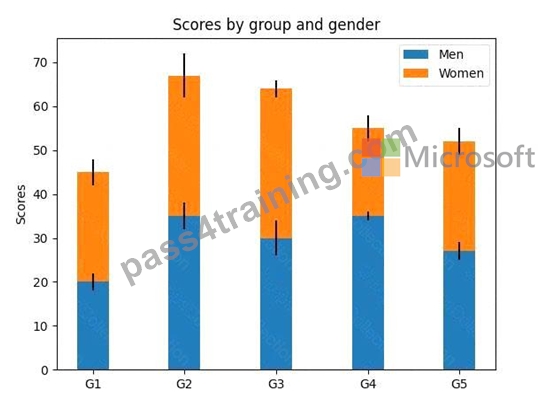
import matplotlib.pyplot as plt
labels = ['G1', 'G2', 'G3', 'G4', 'G5']
men_means = [20, 35, 30, 35, 27]
women_means = [25, 32, 34, 20, 25]
men_std = [2, 3, 4, 1, 2]
women_std = [3, 5, 2, 3, 3]
width = 0.35 # the width of the bars: can also be len(x) sequence
fig, ax = plt.subplots()
ax.bar(labels, men_means, width, yerr=men_std, label='Men')
ax.bar(labels, women_means, width, yerr=women_std, bottom=men_means,
label='Women')
ax.set_ylabel('Scores')
ax.set_title('Scores by group and gender')
ax.legend()
plt.show()
Box 2: two items
Blue item and Green Item.
matplotlib.legend
The legend module defines the Legend class, which is responsible for drawing legends associated with axes and/or figures.
Note: A Diagram Legend is an element that you can add to your diagram to provide information about the colors and/or line thicknesses and styles that have been used in the current diagram, where those colors and other styles have some particular meaning.
https://matplotlib.org/stable/gallery/lines_bars_and_markers/bar_stacked.html
https://matplotlib.org/stable/api/legend_api.html
NEW QUESTION # 28
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are using an Azure Synapse Analytics serverless SQL pool to query a collection of Apache Parquet files by using automatic schema inference. The files contain more than 40 million rows of UTF-8-encoded business names, survey names, and participant counts. The database is configured to use the default collation.
The queries use open row set and infer the schema shown in the following table.
You need to recommend changes to the queries to reduce I/O reads and tempdb usage.
Solution: You recommend defining an external table for the Parquet files and updating the query to use the table Does this meet the goal?
- A. No
- B. Yes
Answer: A
Explanation:
Topic 2, Litware, Inc.
Azure Resources
Litware has the following Azure resources:
* An Azure Synapse Analytics workspace named synapseworkspace1
* An Azure Data Lake Storage Gen2 account named datalake1 that is associated with synapseworkspace1
* A Synapse Analytics dedicated SQL pool named SQLDW
Dedicated SQL Pool
SQLDW contains a dimensional model that contains the following table.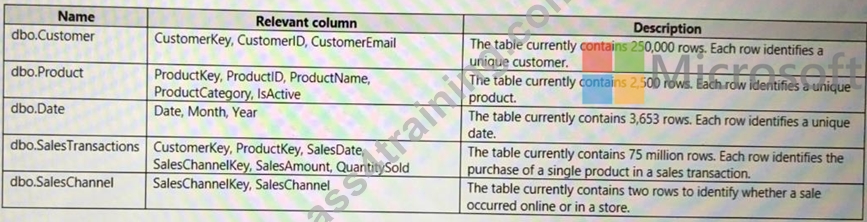
SQLDW contains the following additional tables.
SQLDW contains a view named dbo.CustomerPurchases that creates a distinct list of values from dbo.Customer [customeriD], dbo.Customer
[CustomerEmail], dbo.ProductfProductID] and dbo.Product[ProductName].
The sales data in SQLDW is updated every 30 minutes. Records in dbo.SalesTransactions are updated in SQLDW up to three days after being created. The records do NOT change after three days.
Power BI
Litware has a new Power Bl tenant that contains an empty workspace named Sales Analytics.
All users have Power B1 Premium per user licenses.
IT data analysts are workspace administrators. The IT data analysts will create datasets and reports.
A single imported dataset will be created to support the company's sales analytics goals. The dataset will be refreshed every 30 minutes.
Analytics Goals
Litware identifies the following analytics goals:
* Provide historical reporting of sales by product and channel over time.
* Allow sales managers to perform ad hoc sales reporting with minimal effort.
* Perform market basket analysis to understand which products are commonly purchased in the same transaction.
* Identify which customers should receive promotional emails based on their likelihood of purchasing promoted products.
Litware plans to monitor the adoption of Power Bl reports over time. The company wants custom Power Bl usage reporting that includes the percent change of users that view reports in the Sales Analytics workspace each month.
Security Requirements
Litware identifies the following security requirements for the analytics environment:
* All the users in the sales department and the marketing department must be able to see Power B1 reports that contain market basket analysis and data about which customers are likely to purchase a product.
* Customer contact data in SQLDW and the Power B1 dataset must be labeled as Sensitive. Records must be kept of any users that use the sensitive data.
* Sales associates must be prevented from seeing the CustomerEmail column in Power B1 reports.
* Sales managers must be prevented from modifying reports created by other users.
Development Process Requirements
Litware identifies the following development process requirements:
* SQLDW and datalake1 will act as the development environment. Once feature development is complete, all entities in synapseworkspace1 will be promoted to a test workspace, and then to a production workspace.
* Power Bl content must be deployed to test and production by using deployment pipelines.
* All SQL scripts must be stored in Azure Repos.
The IT data analysts prefer to build Power Bl reports in Synapse Studio.
NEW QUESTION # 29
You are optimizing a dataflow in a Power Bl Premium capacity. The dataflow performs multiple joins. You need to reduce the load time of the dataflow.
Which two actions should you perform? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
- A. Execute non-foldable operations before foldable operations.
- B. Place the ingestion operations and transformation operations in a single dataflow.
- C. Reduce the memory assigned to the dataflows.
- D. Execute foldable operations before non-foldable operations.
- E. Place the ingestion operations and transformation operations in separate dataflows.
Answer: D,E
Explanation:
Explanation
Using the compute engine to improve performance
Take the following steps to enable workloads trigger the compute engine, and always improve performance:
For computed and linked entities in the same workspace:
Ensure you perform the operations that fold, such as merges, joins, conversion, and others.
For ingestion focus on getting the data into the storage as fast as possible, using filters only if they reduce the overall dataset size. It's best practice to keep your transformation logic separate from this step, and allow the engine to focus on the initial gathering of ingredients. Next, separate your transformation and business logic into a separate dataflow in the same workspace, using linked or computed entities; doing so allows for the engine to activate and accelerate your computations. In our analogy, it's like food preparation in the kitchen:
food preparation is typically a separate and distinct step from gathering your raw ingredients, and a pre-requisite for putting the food in the oven. Similarly, your logic needs to be prepared separately before it can take advantage of the compute engine.
Reference:
https://docs.microsoft.com/en-us/power-bi/transform-model/dataflows/dataflows-premium-workload-configurati
NEW QUESTION # 30
The group registers the Power Bl tenant as a data source1.
You need to ensure that all the analysts can view the assets in the Power Bl tenant The solution must meet the technical requirements for Microsoft Purview and Power BI.
What should you do?
- A. Search the data catalog.
- B. Create a linked service.
- C. Deploy a Power Bl gateway.
- D. Create a scan.
Answer: D
NEW QUESTION # 31
You plan to create a Power Bl report that will use an OData feed as the data source. You will retrieve all the entities from two different collections by using the same service root The OData feed is still in development. The location of the feed will change once development is complete.
The report will be published before the OData feed development is complete.
You need to minimize development effort to change the data source once the location changes.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.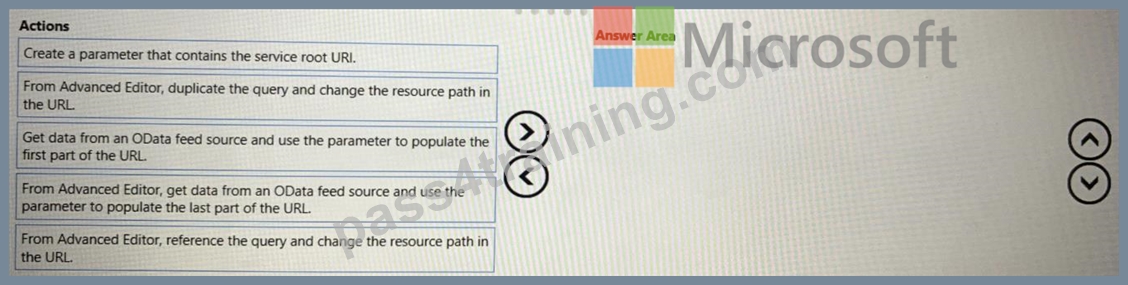
Answer:
Explanation:
1 - Create a parameter that contains the service root URI
2 - Get data from OData feed source and use the parameter to populate the first part of the URL.
3 - From Advanced Editor, duplicate the query and change the resource path in the URL.
NEW QUESTION # 32
You have an Azure Synapse Analytics serverless SQL pool.
You need to return a list of files and the number of rows in each file.
How should you complete the Transact-SQL statement? To answer, drag the appropriate values to the targets.
Each value may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.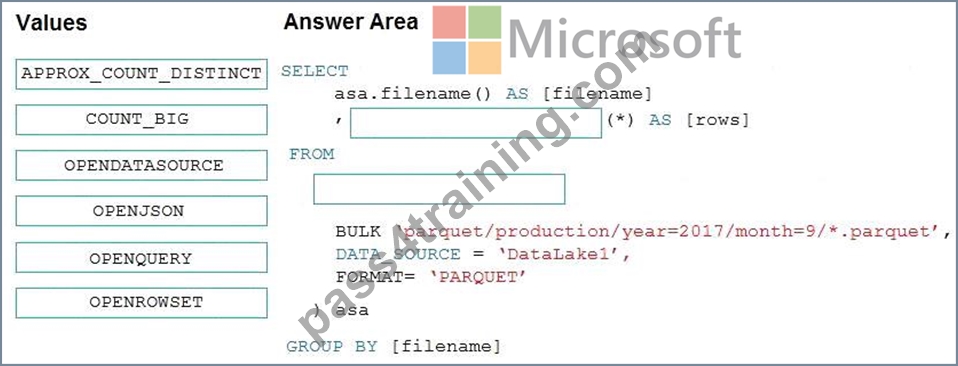
Answer:
Explanation: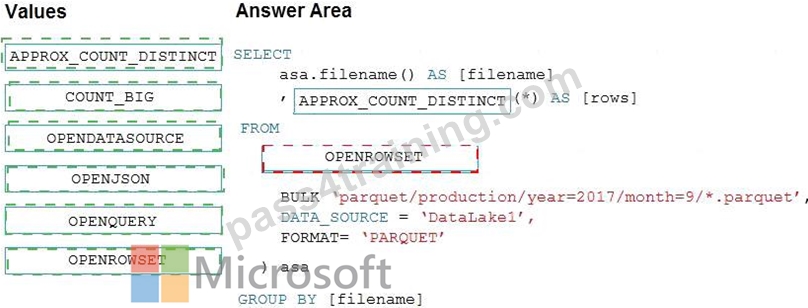
Explanation
Box 1: APPROX_COUNT_DISTINCT
The APPROX_COUNT_DISTINCT function returns the approximate number of unique non-null values in a group.
Box 2: OPENROWSET
OPENROWSET function in Synapse SQL reads the content of the file(s) from a data source. The data source is an Azure storage account and it can be explicitly referenced in the OPENROWSET function or can be dynamically inferred from URL of the files that you want to read. The OPENROWSET function can optionally contain a DATA_SOURCE parameter to specify the data source that contains files.
The OPENROWSET function can be referenced in the FROM clause of a query as if it were a table name OPENROWSET. It supports bulk operations through a built-in BULK provider that enables data from a file to be read and returned as a rowset.
Reference: https://docs.microsoft.com/en-us/sql/t-sql/functions/approx-count-distinct-transact-sql
https://docs.microsoft.com/en-us/azure/synapse-analytics/sql/develop-openrowset
NEW QUESTION # 33
You have a Power Bl data model.
You need to refresh the data from the source every 15 minutes.
What should you do first?
- A. Enable the XMLA endpoint.
- B. Configure a scheduled refresh.
- C. Change the storage mode of the dataset.
- D. Define an incremental refresh policy.
Answer: B
Explanation:
To get to the Scheduled refresh screen:
1. In the navigation pane, under Datasets, select More options (...) next to a dataset listed.
2. Select Schedule refresh.
NEW QUESTION # 34
You have a 2-GB Power Bl dataset.
You need to ensure that you can redeploy the dataset by using Tabular Editor. The solution must minimize how long it will take to apply changes to the dataset from powerbi.com.
Which two actions should you perform in powerbi.com? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point
- A. Enable XMLA read-write.
- B. Turn on Large dataset storage format.
- C. Connect the target workspace to an Azure Data Lake Storage Gen2 account.
- D. Enable service principal authentication for read-only admin APIs.
Answer: A,B
Explanation:
Optimize datasets for write operations by enabling large models
When using the XMLA endpoint for dataset management with write operations, it's recommended you enable the dataset for large models. This reduces the overhead of write operations, which can make them considerably faster. For datasets over 1 GB in size (after compression), the difference can be significant.
Tabular Editor supports Azure Analysis Services and Power BI Premium Datasets through XMLA read/write.
Note: Tabular Editor - An open-source tool for creating, maintaining, and managing tabular models using an intuitive, lightweight editor. A hierarchical view shows all objects in your tabular model. Objects are organized by display folders with support for multi-select property editing and DAX syntax highlighting. XMLA read-only is required for query operations. Read-write is required for metadata operations.
Reference:
https://tabulareditor.github.io/
NEW QUESTION # 35
You need to configure a source control solution for Azure Synapse Analytics. The solution must meet the following requirements:
* Code must always be merged to the main branch before being published, and the main branch must be used for publishing resource
* The workspace templates must be stored in the publish branch.
* A branch named dev123 will be created to support the development of a new feature.
What should you do? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Answer:
Explanation:
NEW QUESTION # 36
You use the Vertipaq Analyzer to analyze tables in a dataset as shown in the Tables exhibit. (Click the Tables tab.)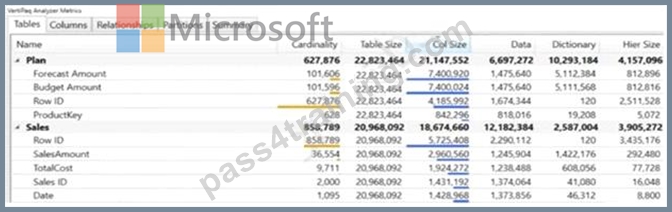
The table relationships for the dataset are shown in the Relationships exhibit. (Click the Relationships tab.)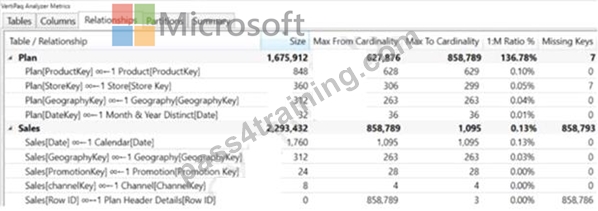
You need to reduce the model size by eliminating invalid relationships.
Which column should you remove?
- A. Sales[Sales ID]
- B. Plan[RowlD]
- C. Sales[RowlD]
- D. Sales[Sales Amount]
Answer: C
Explanation:
Sales[Row ID] has 858,786 missing keys and 858,789 Max From Cardinality.
Note: The Max From Cardinality column defines the cost of the relationship which is the amount of time DAX needs to transfer the filters from the dimensions table to the fact table.
NEW QUESTION # 37
You have a kiosk that displays a Power Bl report page. The report uses a dataset that uses Import storage mode. You need to ensure that the report page updates all the visuals every 30 minutes. Which two actions should you perform? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
- A. Configure the data sources to use a streaming dataset
- B. Enable Power Bl embedded.
- C. Add a Microsoft Power Automate visual to the report page.
- D. Configure the data sources to use DirectQuery.
- E. Enable the XMIA endpoint.
- F. Select Auto page refresh.
Answer: D,F
Explanation:
Automatic page refresh in Power BI enables your active report page to query for new data, at a predefined cadence, for DirectQuery sources.
Automatic page refresh is available for DirectQuery sources and some LiveConnect scenarios, so it will only be available when you are connected to a supported data source. This restriction applies to both automatic page refresh types.
NEW QUESTION # 38
You have an Azure Synapse Analytics serverless SQL pool.
You need to catalog the serverless SQL pool by using Azure Purview.
Which three actions should you perform? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
- A. Register a data source.
- B. Create a managed identity in Azure Active Directory (Azure AD).
- C. Assign the Storage Blob Data Reader role to the Azure Purview managed service identity (MSI) for the storage account associated to the Synapse Analytics workspace.
- D. Assign the Owner role to the Azure Purview managed service identity (MSI) for the Azure Purview resource group.
- E. Assign the Reader role to the Azure Purview managed service identity (MSI) for the Synapse Analytics workspace.
Answer: B,C,E
Explanation:
Explanation
Authentication for enumerating serverless SQL database resources
There are three places you'll need to set authentication to allow Microsoft Purview to enumerate your serverless SQL database resources:
The Azure Synapse workspace
The associated storage
The Azure Synapse serverless databases
The steps below will set permissions for all three.
Azure Synapse workspace
In the Azure portal, go to the Azure Synapse workspace resource.
On the left pane, selectAccess Control (IAM).
Select the Add button.
Set the Reader role and enter your Microsoft Purview account name, which represents its managed service identity (MSI).
Select Save to finish assigning the role
Azure Synapse Analytics serverless SQL pool catalog Purview Azure Purview managed service identity Storage account In the Azure portal, go to the Resource group or Subscription that the storage account associated with the Azure Synapse workspace is in.
On the left pane, selectAccess Control (IAM).
Select the Add button.
Set the Storage blob data reader role and enter your Microsoft Purview account name (which represents its MSI) in the Select box.
Select Save to finish assigning the role.
Azure Synapse serverless database
Go to your Azure Synapse workspace and open the Synapse Studio.
Select the Data tab on the left menu.
Select the ellipsis (...) next to one of your databases, and then start a new SQL script.
Add the Microsoft Purview account MSI (represented by the account name) on the serverless SQL databases.
You do so by running the following command in your SQL script:
SQL
CREATE LOGIN [PurviewAccountName] FROM EXTERNAL PROVIDER;
Apply permissions to scan the contents of the workspace
You can set up authentication for an Azure Synapse source in either of two ways. Select your scenario below for steps to apply permissions.
Use a managed identity
Use a service principal
Reference: https://docs.microsoft.com/en-us/azure/purview/register-scan-synapse-workspace?tabs=MI
NEW QUESTION # 39
You have a team of business analysts that uses Power Bl for departmental analytics.
The team creates and manages PBIX files.
You need to implement a source control solution for the PBIX files. The solution must meet the following requirements:
* Provide version tracking and roll back.
* Minimize version conflicts between edits.
* Ensure that all the analysts can access the files.
* Prevent multiple analysts from editing the same version of a file.
What should you include in the solution? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.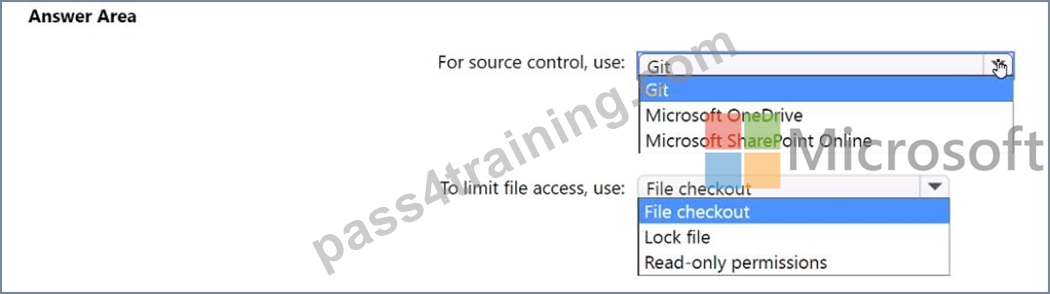
Answer:
Explanation: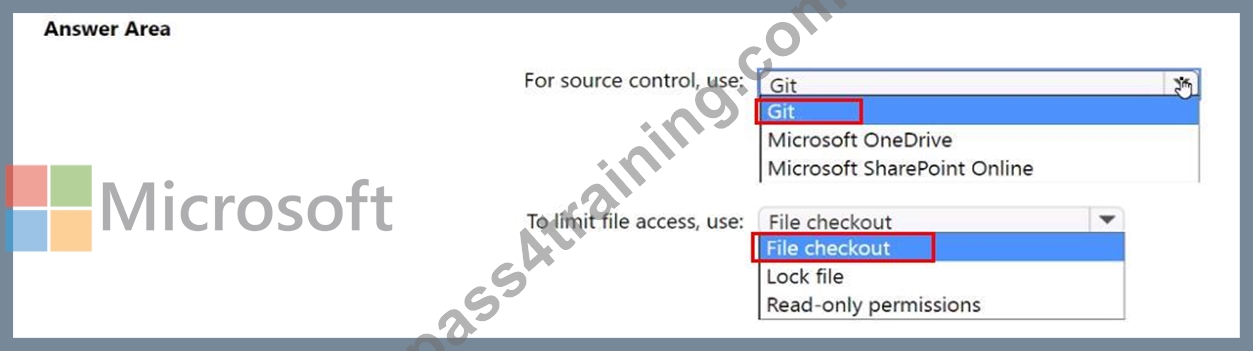
NEW QUESTION # 40
You have a shared dataset in Power Bl named Dataset1.
You have an on-premises Microsoft SQL Server database named DB1.
You need to ensure that Dataset1 refreshes data from DB1.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of
actions to the answer area and arrange them in the correct order.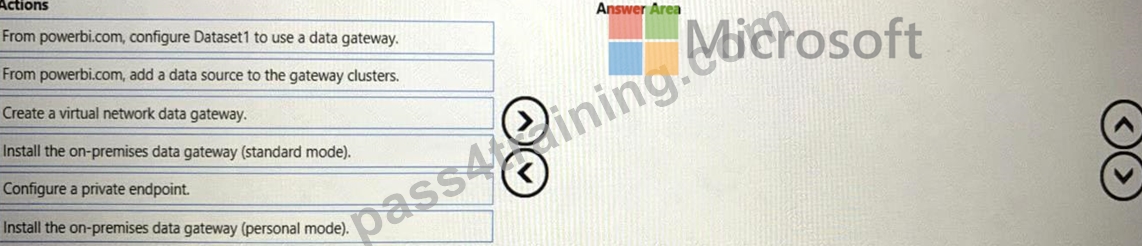
Answer:
Explanation: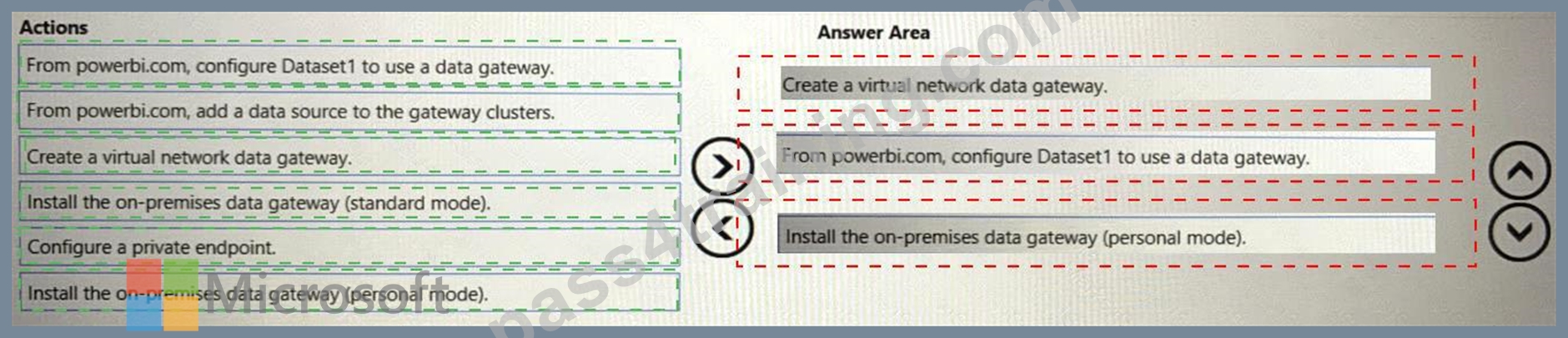
NEW QUESTION # 41
......
DP-500 Certification All-in-One Exam Guide May-2024: https://www.pass4training.com/DP-500-pass-exam-training.html
Easily To Pass New DP-500 Premium Exam: https://drive.google.com/open?id=1QytibWFG4zlU0QKkW_t6IhStOlS4hqsh